'%3e%3crect%20x='79'%20y='10'%20width='5'%20height='34'%20fill='%23020B11'%20style='mix-blend-mode:multiply'/%3e%3c/g%3e%3cpath%20d='M86%20139C60.6%20139%2040%20118.4%2040%2093C40%2067.6%2060.6%2047%2086%2047V7C38.5%207%200%2045.5%200%2093C0%20140.5%2038.5%20179%2086%20179V139Z'%20fill='%23025FEB'/%3e%3cdefs%3e%3cfilter%20id='filter0_f_206_318'%20x='69'%20y='0'%20width='25'%20height='54'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='BackgroundImageFix'%20result='shape'/%3e%3cfeGaussianBlur%20stdDeviation='5'%20result='effect1_foregroundBlur_206_318'/%3e%3c/filter%3e%3c/defs%3e%3c/svg%3e)
Launcher
assignment_notebook.ipynb
Markdown
Python (Pyodide)
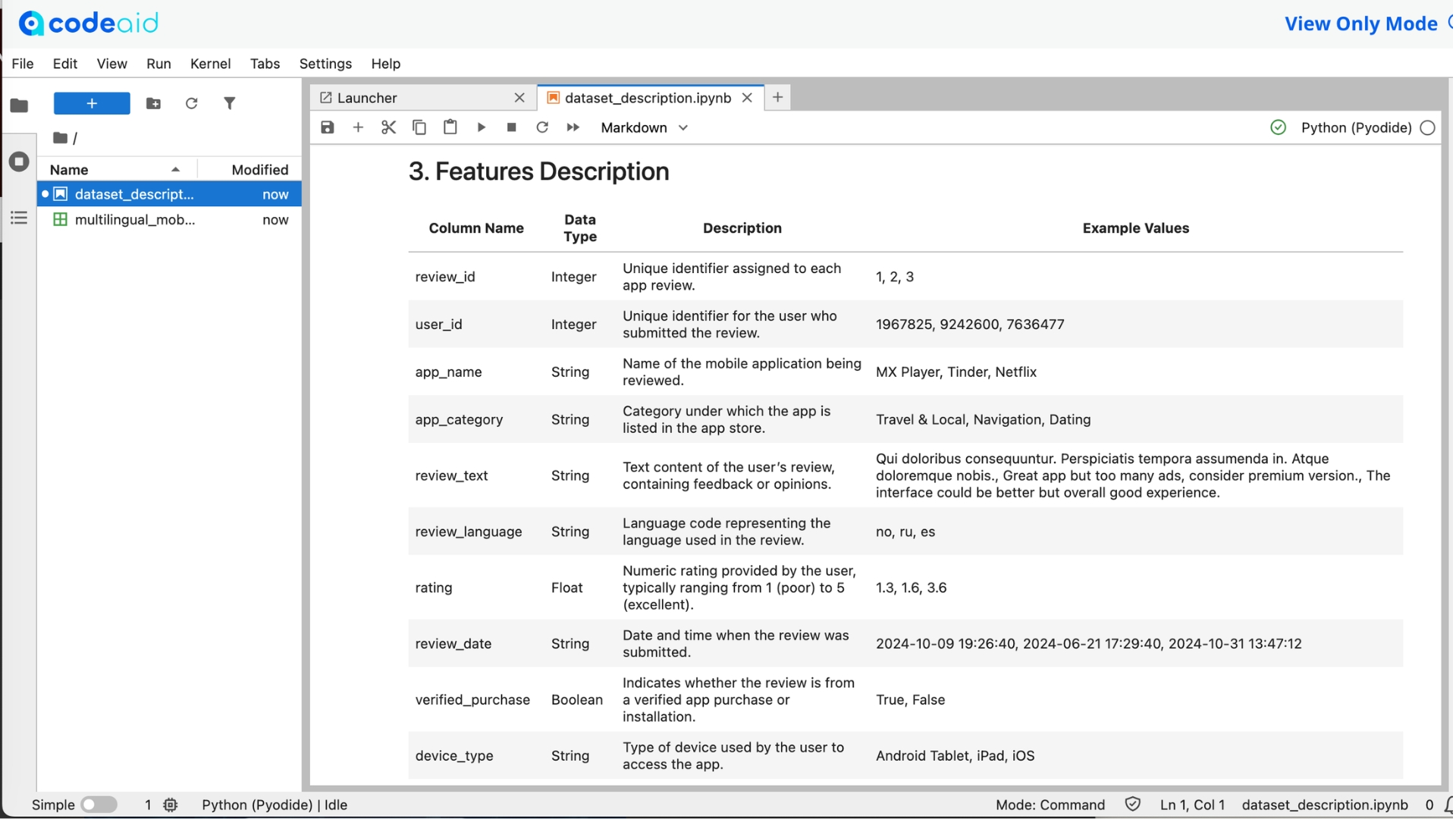
features (X), labels (y), "optimizer"(str), "scheduler"(str), "device"(str)
[ ]:
def build_training_pipeline(*args, **kwargs):
"""Create train/validation loaders and initialize model, optimizer,
scheduler, criterion, and mixed-precision training config.
Args:
config: dict
train_df: pandas.DataFrame
val_df: pandas.DataFrame
Returns:
model: torch.nn.Module
optimizer: torch.optim.Optimizer
scheduler: torch.optim.lr_scheduler._LRScheduler
"""
# Your code for this task here
# Reuse the same notebook structure and modify signature if needed
pass
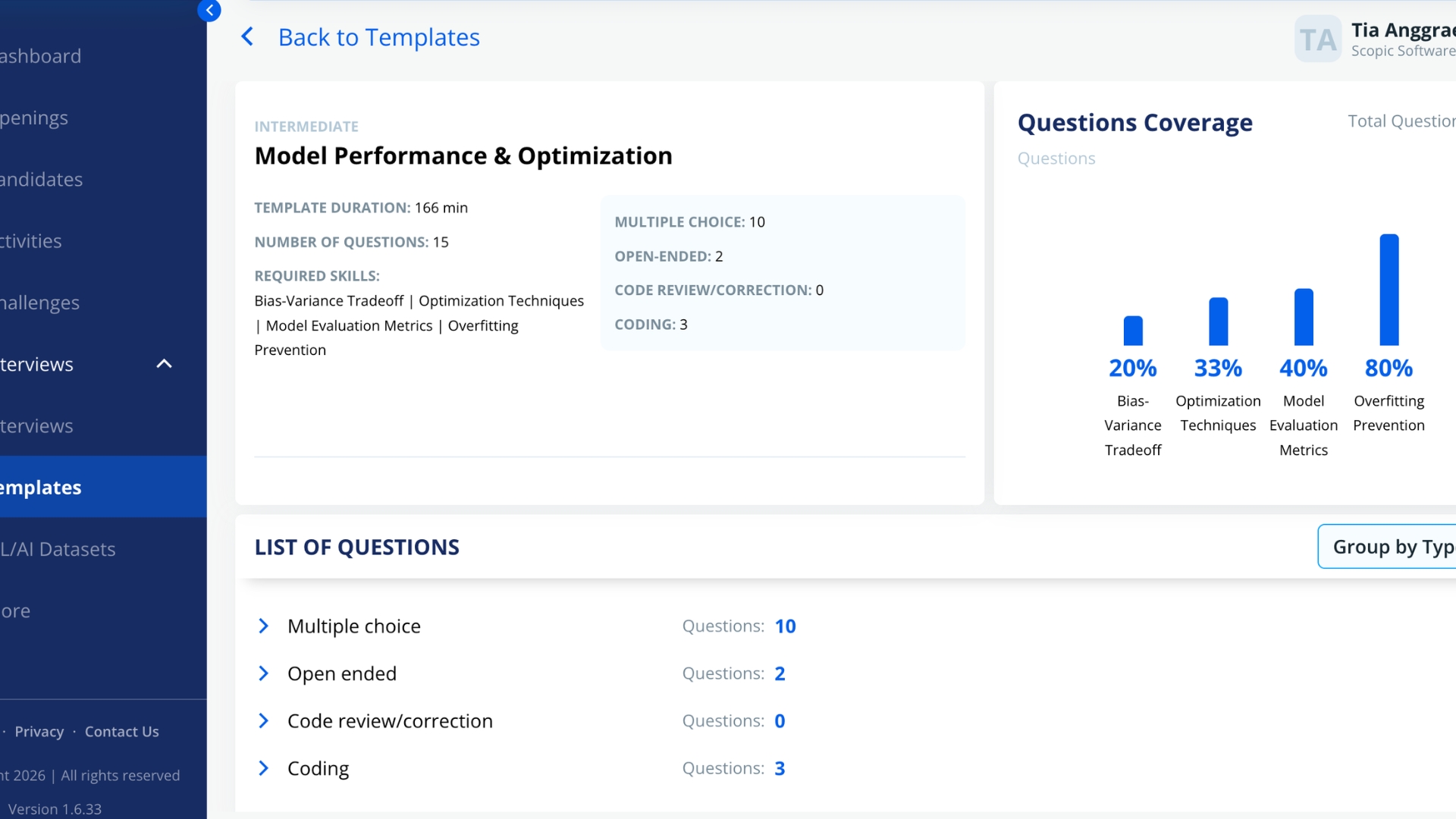
Task 3: Implement deep learning training loop with early stopping, gradient clipping, and validation tracking
[ ]:
def train_model(model, train_loader, val_loader, optimizer, scheduler, criterion, scaler, device):
"""Train a neural network and track train_loss, val_loss, val_f1,
learning rate schedule, and best checkpoint state.
Args:
model: torch.nn.Module
train_loader: torch.utils.data.DataLoader
val_loader: torch.utils.data.DataLoader
Returns:
history: dict[str, list[float]]
best_state_dict: dict[str, torch.Tensor]
"""
# Train for N epochs with mixed precision
# Apply gradient clipping and patience-based early stopping
pass
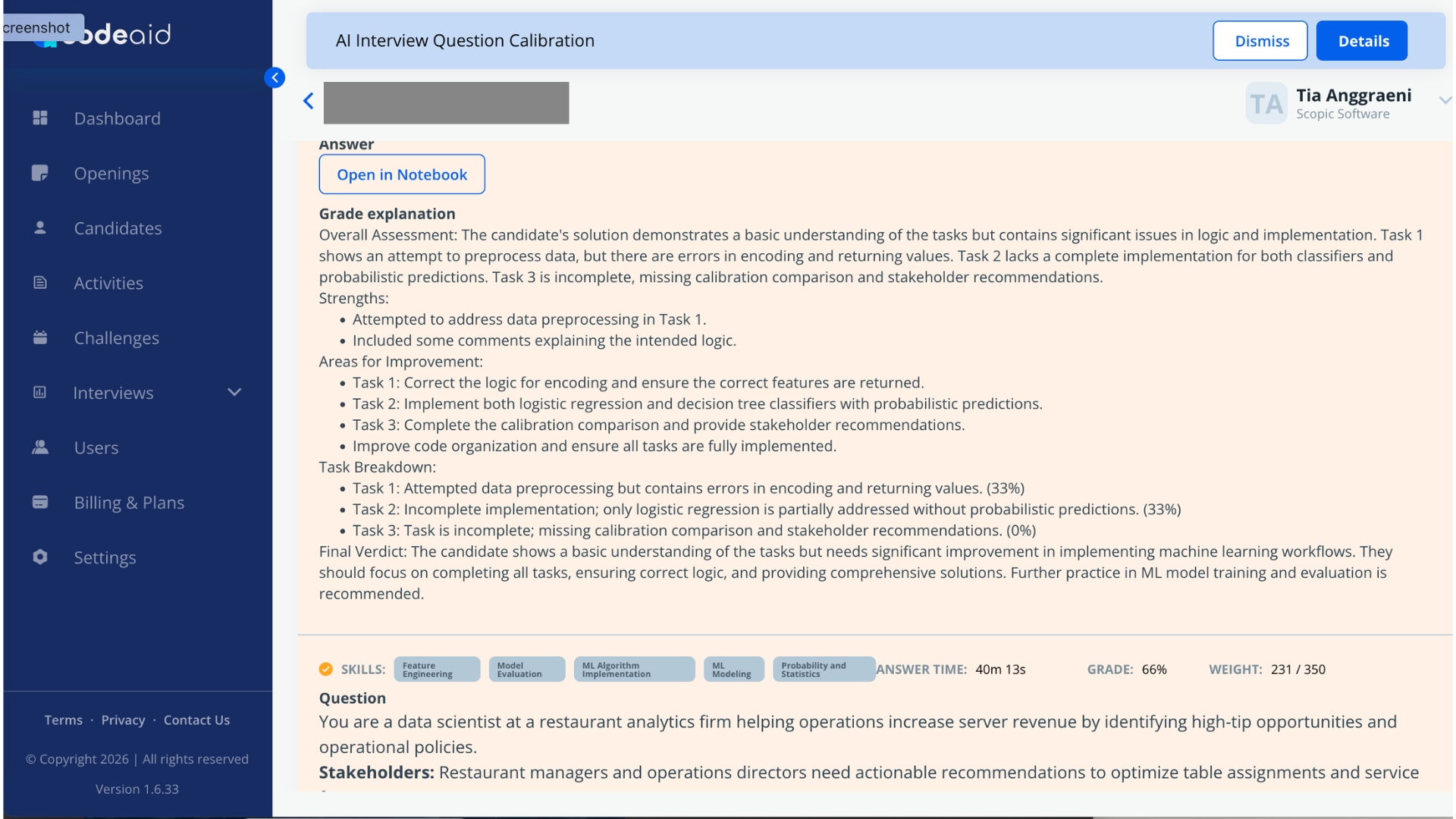
[ ]:
def evaluate_model(model, dataloader, criterion, device):
"""Compute validation loss, accuracy, F1, AUROC, and confusion matrix."""
# Return both aggregate metrics and raw predictions
pass
Epoch 12/30
train_loss: 0.1842 | val_loss: 0.2217 | val_f1: 0.912 | lr: 0.0003
early_stopping_counter: 2/5 | gradient_clip_norm: 1.0